
MySQL 主从同步
前言
在此前的 MySQL 日志笔记中已经简单提到归档日志(binlog)的可以用于主从同步和数据备份,但是并没有详细提到 MySQL 主从同步的原理以及实现方式,那么这篇笔记就会详细去讲述 MySQL 的主从同步。借用 《MySQL 实战 45 讲》中的话,MySQL 能够成为如此流行的数据库,能够拥有如此高可用的架构,都离不开归档日志实现的主从同步
基础概念
1、什么是主从同步?
简单说来主从同步就是让主数据库和从数据库之间的数据保持同步
通常主数据库就是用于执行各种更新操作,称为主库;通常从数据库就是作为主库的备份,称为从库
至于两者配合的形式以及具体的同步方式接下来就会立刻讲述
主从形式
首先会介绍两种最为常见的基本机构,后续的结构可以认为就是在这种结构上进行改进的
一主一从结构(M-S 结构):仅存在单个主数据库,单个从数据库
- 访问形式:主库可以执行任意的更新和查询操作,从库会设置为只读形式,也就是仅可以执行查询操作
- 同步原理:每次主库发生更新操作后都会将归档日志发送给从库,从库接收到归档日志后就会执行归档日志,从而实现数据同步

主主结构(双 M 结构):仅存在两个数据库,两个数据库互为主数据库
- 访问形式:两个数据库都可以对外提供读写服务,但如果一个正在执行更新操作,另一个就会“自动“设置为只读,仅提供查询
- 这里的自动实际上是需要采用某些手段进行控制的,从而避免同时向两个数据库写入的情况,通常有以下两种方式
- 基于自主主键的控制
- 基于库级别的或者基于表级别的控制
- 这里的自动实际上是需要采用某些手段进行控制的,从而避免同时向两个数据库写入的情况,通常有以下两种方式
- 同步原理:
- 每次主库发生更新之后依然会发送归档日志给从库进行数据同步,但是从库也会向主库发送归档日志进行数据同步
- 设计相互发送的目的是因为主库可以自动发生变化,变化后就要重设接收归档日志的位置,就相当于依然要手动更改主库
- 现在直接让两个主数据库互相发送归档日志,就可以避免手动输入命令切换主库,从而实现快速切换主库
- 双主结构的好处就在于能够更加快速的切换主库,因为不需要手动切换(?),但是存在数据不一致的问题

- 访问形式:两个数据库都可以对外提供读写服务,但如果一个正在执行更新操作,另一个就会“自动“设置为只读,仅提供查询
如下三种结构就是在上面两种基础结构进行的改进,这里就不再做详细介绍
- 一主多从结构:仅存在单个主数据库,但是存在多个从数据库
- 多主一从结构:仅存在单个从数据库,但是存在多个主数据库
- 联级复制结构

真实的数据库架构设计应该是多个主数据库和多个从数据库,然后会使用 MyCat 等中间件来完成数据库的负载均衡,从而降低数据库的压力
潜在“问题”
在介绍了两种基础的数据库架构之后,你可能存在一定的疑问,不要着急,接下来就会详细解释
为什么要将从库设置为只读形式?
- 主从同步通常会用于读写分离,也就是仅在从库上执行查询操作,所以设置为只读模式是为了防止在从库上执行更新的误操作
- 可以通过是否设置为只读模式从而区分数据库的角色,也就是哪个是主库,哪个是从库
- 防止在主备切换的过程中出现双写的情况,从而造成数据不一致
从库被设置为只读形式,而执行归档日志是更新操作,两者不应该是矛盾的吗?
- 每个数据库中都会设计超级权限的存在,具有超级权限的用户或者线程是不会受到只读模式的影响的
- 而从库中执行归档日志的更新线程就是具有超级权限的,所以可以无视设置的只读模式进行更新
双 M 结构不会造成循环复制问题吗?
- 什么是循环复制问题?
- 在主库执行更新操作之后就会将归档日志发送给从库,而从库接收到归档日志并执行后又会发送回给主库
- 而主库在接收到归档日志又会去执行更新操作,然后再发送归档日志给从库执行,这就造成了死循环
- 如何解决循环复制问题?解决的方式非常简单
- 每个数据库在其配置文件中都会设置 server_id,确保主库和从库的 server_id 不同,如果相同则不能够互为主从关系
- 每次主库向从库发送的归档日志中就会写入数据库的 server_id
- 如果数据库接收到的归档日志记录的 server_id 和自己拥有的 server_id 不同,就会执行归档日志
- 反之,就不会去执行归档日志,从而让循环复制断开
- 什么是循环复制问题?
核心机制
在此之前讲述主从同步的基本架构和原理,以及可能存在的疑惑,但是并没有讲述主库和从库内部到底是如何控制归档日志,并实现数据同步,接下来就会详细讲述这部分的内容。先来大致看下这张图中的内容,就可以知道主从同步的基本流程是如何执行的。
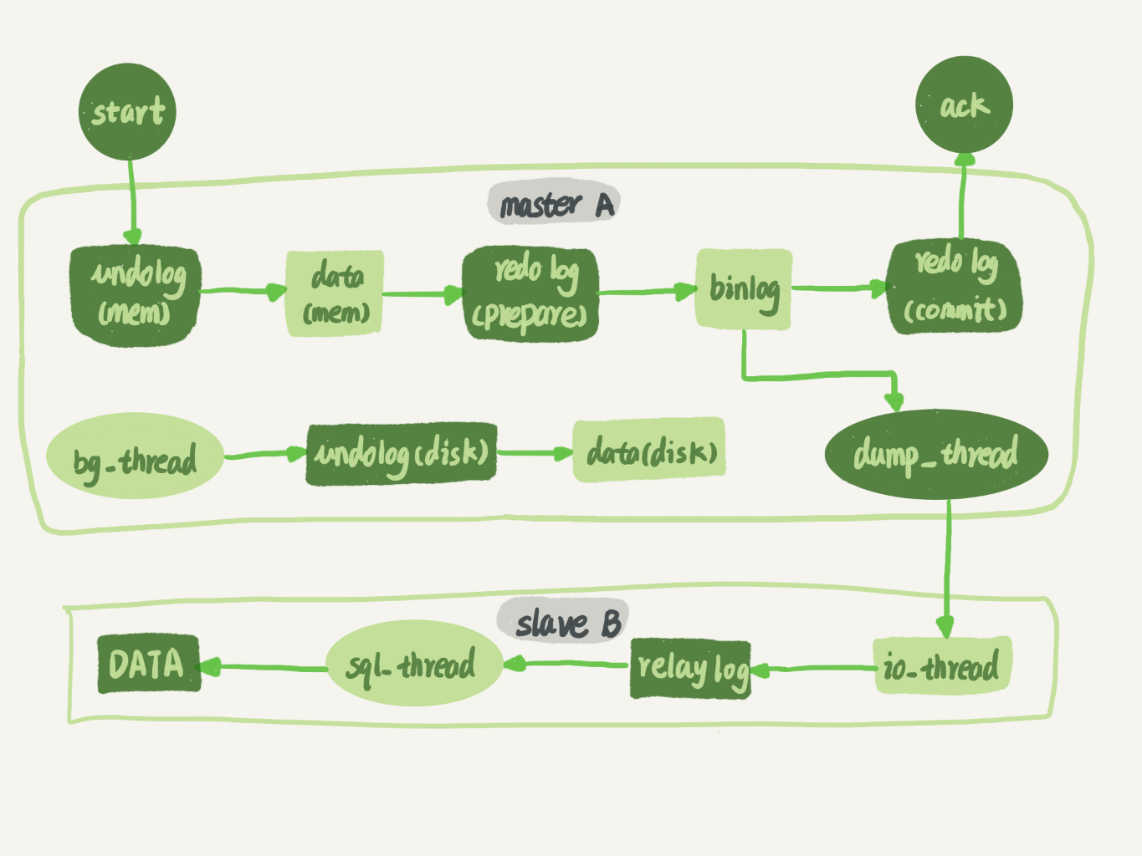
主库和从库之间会通过命令设置相关信息建立长连接,然后分别开启相应的线程去负责归档日志的发送、接收、执行等过程,从而确保主从同步能够顺利执行
从库使用
change master命令设置相关的信息,然后就会开启io_thread和sql_thread分别负责接收和执行归档日志- 相关信息:从库访问主库的用户名和密码,IP 地址和端口号,访问的归档日志的文件名以及起始位置
主库更新内存中的数据并向内存中写入重做日志,然后开启两阶段提交机制,完成重做日志的持久化后,就会开始向从库发送重做日志
主库再验证从库发送的用户名和密码,以及对应的重做日志和起始位置,然后通过
dump_thread线程发送归档日志从库就通过
io_thread从主库中接收发送过来的归档日志,并且将其持久化到磁盘中称为中转日志(relay_log)- 将归档日志持久化存储到磁盘的目的是为了让其他线程去执行归档日志
io_thread线程能够继续接收中转日志,而不用等待中转日志执行结束,从而实现异步的效果,提高同步的效率
最后从库就通过
sql_thread并采用合适的并行策略开始解析中转日志中的内容并且执行,从而完成数据同步- 解析并执行归档日志中的内容是非常消耗时间的,所以会采用适当的并行策略来加速执行,从而减少主备延迟
- 至于并行策略和主备延迟两个内容会在之后详细讲述
2、为什么采用主从同步?
在之前已经提到从库通常是作为主库的备份存在,为什么采用主从同步这个问题也就变成为什么要采用从库作为备份这个问题,这个备份到底可以应对什么样的情况呢?
- 读写分离:主库仅执行更新操作,从库负责执行所有的查询操作,从而降低主库的压力
- 容灾备份:在主库突然宕机故障之后,能够立刻将备库切换为主库继续提供相应的服务
- 数据备份:在出现误操作或者数据丢失之后,能够利用备库中保存的数据恢复主库中丢失的数据
注:读写分离是最为重要的用途,之后还会详细介绍读写分离存在的问题
3、归档日志的格式
在此前介绍归档日志的笔记中,实际上已经提到归档日志的三种日志格式了,但是没有详细提到每种格式内部到底的怎么样,如何才能够看到内部的内容,这部分内容就会补全之前缺失的部分, 不过不是很重要,更加偏向实战,基本特点都在之前已经提过了
3.1、STATEMENT
① 归档日志默认记录格式是 ROW,所以需要提前修改归档日志的记录格式
# 设置 binlog 格式 |

② 找到已经存储了记录的数据库中的表,然后随意执行一条更新语句即可
# 删除相应的数据: 这里只会删除一条数据, 也就是最后一条, 这是根据索引查询出来的结果集而定的 |

③ 然后找打开该行记录可能存在的 binlog 文件(通常都是最新的那个,在 data 文件夹下可以看到)
# 打开对应的 binlog |

SET @@SESSION.GTID_NEXT= ‘ANONYMOUS’:
可以看到在事务之间执行的 SQL 语句被非常完整的保存下来了
delete from category where category_pid = 15 limit 1;
BEGIN 和 COMMIT 显然都是事物的标志;XID 是用于联系重做日志的标志
3.2、ROW
① 再将归档日志格式切换回 ROW 格式
② 然后执行任意的更新语句后查询 binlog 文件
你会发现此时记录的内容,是你看不懂的东西,所以这个时候就需要依赖 mysqlbinlog 工具来解析 binlog 文件
③ 解析 binlog 文件
mysqlbinlog -vv data/master.000039 --start-position=8900; |
即使我执行的是 delete 语句,row 格式的 binlog 也会把被删掉的行的整行信息保存起来。所以,如果你在执行完一条 delete 语句以后,发现删错数据了,可以直接把 binlog 中记录的 delete 语句转成 insert,把被错删的数据插入回去就可以恢复了。如果你是执行错了 insert 语句呢?那就更直接了。row 格式下,insert 语句的 binlog 里会记录所有的字段信息,这些信息可以用来精确定位刚刚被插入的那一行。这时,你直接把 insert 语句转成 delete 语句,删除掉这被误插入的一行数据就可以了。如果执行的是 update 语句的话,binlog 里面会记录修改前整行的数据和修改后的整行数据。所以,如果你误执行了 update 语句的话,只需要把这个 event 前后的两行信息对调一下,再去数据库里面执行,就能恢复这个更新操作了
3.3、 MIXED
参考资料
《Mysql主从基本原理,主要形式以及主从同步延迟原理 (读写分离)导致主库从库数据不一致问题的及解决方案》
《MySQL 实战 45 讲》
实战配置
在了解主从同步的基本概念之后,先不去详细了解主从同步潜在的问题,先来看看主从同步大致是如何配置的
整个过程虽然并不困难,但是可能存在许多奇怪的问题,但是这篇文章是在我配置结束很久之后写的,所以部分问题可能无法复现
1、搭建多个 MySQL 实例的基本前提
如果拥有两台云服务器,就非常容易配置两个不同的数据库,只需要在每台服务器上都安装 MySQL 就可以了
如果只有一台云服务器,那么就不要想着让本地计算机的 MySQL 作为主库,让云服务器作为从库。因为云服务器上的从库必须从主库获取相应归档日志才能够实现主从同步,但是你的本地计算机是根本没有公网地址的(如果你有公网地址,那就当我没说),所以云服务器是无法检测到你的本地计算机上的主库的
这也是接下来要讲述的,如何在本地计算中配置多个 MySQL 实例
2、准备从库需要的基本数据
首先将主库中的数据 全部拷贝 到从数据库文件夹下:这里将 mysql-5.7.33-winx64 下的数据全部拷贝到 mysql-backup 中
这里千万注意一定是所有的数据,而不要只拷贝部分数据库实例,因为所有数据库实例的二次缓冲、事务等相关信息都是存储在共享文件表(ibdata1),如果只拷贝部分数据库实例,那么就会出现共享文件表记录的有关信息,但是关联的数据库却是不存在的情况,这样从库启动后就会出现问题

3、修改配置文件
找到你的数据库的配置文件所在的位置,然后进行修改,主要修改的就是端口号,不可以和主库的端口号相同
[mysqld] |
4、直接安装新的 MySQL 实例
用 管理员身份 打开终端然后输入相应的命令:
- 如果出现
Service successfully installed就是安装成功 - 如果是
Install/Remove of the Service Denied!那么就是没有使用管理员身份打开终端
注:如果你此前 MySQL 已经配置了环境变量,那么就不用切换到 bin 目录下,直接输入命令就行
# --defaults-file 后面跟的就是你的配置文件所在路径 |
安装完成后,就打开任务管理器去启动 MySQL 实例。这个方法比较简单粗暴,因为有时候使用其他的命令,命令的影响可能是全局的,不要乱用
比如重新初始化仓库中的数据,以及卸载等命令,千万不要乱用,很有可能主库从库的数据全部都被清除,或者一起被卸载

也可以尝试使用各种连接工具去连接相应的数据库,可以使用以下的命令,使用的账号密码和主库中保存的是相同的。记得,端口号一定是大写的 P,密码一定是小写的 p,千万不要整错了
mysql -P3308 -uroot -p |

如果你还想要验证是否连接的就是端口号为 3308 的从库,而不是端口号为 3306 的主库,完全可以在从库中写入数据,然后观察主库是否有相应的变化,就可以了,至此,MySQL 实例就算安装完成了,接下来就是主从同步相关
如果出现其他问题,那么请怀疑你自身是不是哪里做错了,因为这里是经过测试确认成功的
5、设置主从同步需要的配置文件
先在主库的配置文件添加如下的配置:每个 MySQL 实例必须具有不同的 server-id,否则也是启动之后会出现错误,也有可能启动不了
# 配置主数据库 ID |
然后在从库的配置文件中添加如下的配置
server-id=3 |
主库和从库的配置文件更新完成之后,就分别重启主库和从库,建议从任务管理中重启
6、调试主从同步
先在主库中输入相应的命令,检查是否有对应的归档日志
show master status; |

然后在主库中创建新的用户,用于从库访问主库的时候使用,并授予相应的权限
# 创建相应的用户 |
然后在从库中设置主库的地址、端口号以及访问主库的用户名,还有从哪个归档日志中的哪个位置开始读取
change master to |
然后查看从库是否完成主从同步,此时可能会发现下面抛出了 IO 异常信息(这次配置没有复现这个错误),或者什么都没有抛出,但是你如果尝试在主库中更新,从库中是不会更新的。原因是因为你之前直接复制了主库的内容,导致主库和从库中的 UUID 是完全相同,所以需要去修改从库中的 UUID
# 查看主从同步状态 |
先停止主从同步,然后去数据库实例下的仓库文件夹中找到 auto.cnf 文件,将 UUID 修改为和主库不同的即可,这里也就是去 D:\MySQL\mysql-5.7.33-winx64\mysql-backup\data 文件夹下找到 auto.cnf 文件进行修改
# 停止主从同步 |
最后在主库中执行更新操作,验证下即可
参考资料